Introduction to State-Of-The-Art Speech Recognition Techniques
Written on March 4th, 2022 by Théo Gigant
Illustration: Portrait of a Scribe (Bartolomeo Passerotti, 1560)
From January 24th to February 7th 2022, I joined HuggingFace’s Robust Speech Challenge and fine-tuned a Romanian Speech Recognition model that ranked Top-1 on the event leaderboard and even beat the previous state of the art on Mozilla Foundation’s Common Voice test split.
Here is a comprehensive blog post about the technologies involved.
You can :
-
Check the model card and download the model on HuggingFace’s Model Hub here.
-
Try the model with a Gradio web app on a HuggingFace Space here.
This blog post will cover :
- How to use this model for romanian speech recognition, using the
transformerslibrary for python - The Wav2Vec2 acoustic model
- The speech recognition task, with an example of a method to perform this task using a pretrained acoustic model
- Language model boosting for Speech Recognition
How to use this model for Romanian Speech Recognition
Make sure you have installed the correct dependencies for the language model-boosted version to work. You can just run this command to install the kenlm and pyctcdecode libraries :
pip install https://github.com/kpu/kenlm/archive/master.zip pyctcdecode
With the framework transformers you can load the model with the following code :
from transformers import AutoProcessor, AutoModelForCTC
processor = AutoProcessor.from_pretrained("gigant/romanian-wav2vec2")
model = AutoModelForCTC.from_pretrained("gigant/romanian-wav2vec2")
Or, if you want to test the model, you can load the automatic speech recognition pipeline from transformers with :
from transformers import pipeline
asr = pipeline("automatic-speech-recognition", model="gigant/romanian-wav2vec2")
Example use with the datasets library
First, you need to load your data
We will use the Romanian Speech Synthesis dataset in this example.
from datasets import load_dataset
dataset = load_dataset("gigant/romanian_speech_synthesis_0_8_1")
You can listen to the samples with the IPython.display library :
from IPython.display import Audio
i = 0
sample = dataset["train"][i]
Audio(sample["audio"]["array"], rate = sample["audio"]["sampling_rate"])
The model is trained to work with audio sampled at 16kHz, so if the sampling rate of the audio in the dataset is different, we will have to resample it.
In the example, the audio is sampled at 48kHz. We can see this by checking dataset["train"][0]["audio"]["sampling_rate"]
The following code resample the audio using the torchaudio library :
import torchaudio
import torch
i = 0
audio = sample["audio"]["array"]
rate = sample["audio"]["sampling_rate"]
resampler = torchaudio.transforms.Resample(rate, 16_000)
audio_16 = resampler(torch.Tensor(audio)).numpy()
To listen to the resampled sample :
Audio(audio_16, rate=16000)
Know you can get the model prediction by running
predicted_text = asr(audio_16)
ground_truth = dataset["train"][i]["sentence"]
print(f"Predicted text : {predicted_text}")
print(f"Ground truth : {ground_truth}")
How to make the model work with large audio files?
To make sure the model will work with arbitrarly large audio files, we will have to use a trick involving the parameters chunk_length_s and stride_length_s of the automatic speech recognition pipeline in transformers.
What chunking is doing is cutting the input in chunks of a fixed length (chosen with the parameter chunk_length_s), overlaped with strides of a fixed length (chosen with the parameter stride_length_s).
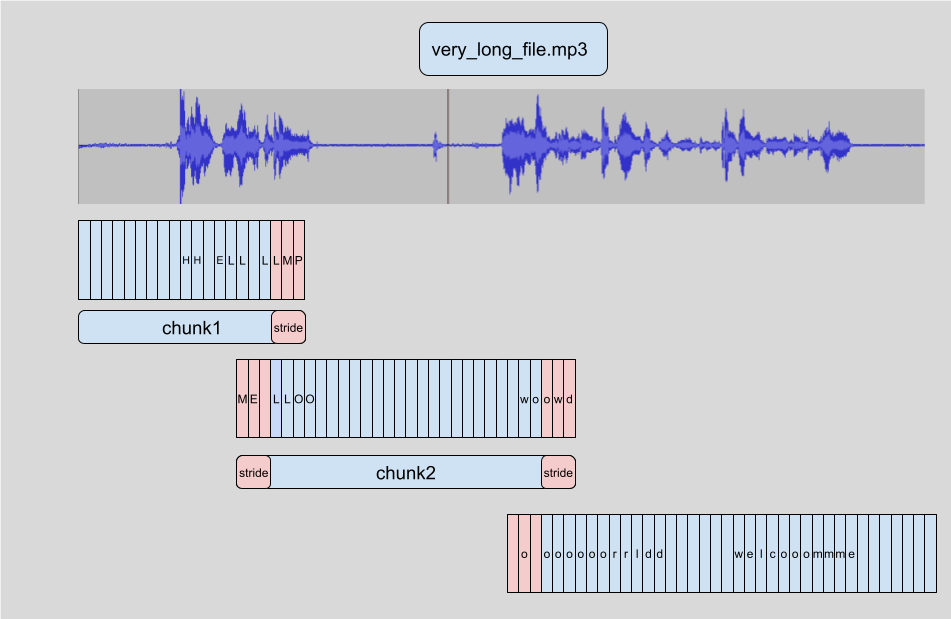
To use this trick in transformers with an automatic speech recognition pipeline you can just give the parameters when using the pipeline (the values are the lengths in seconds) :
from transformers import pipeline
asr = pipeline("automatic-speech-recognition", model="gigant/romanian-wav2vec2")
# stride_length_s is a tuple of the left and right stride length.
# With only 1 number, both sides get the same stride, by default
# the stride_length on one side is 1/6th of the chunk_length_s
output = asr("very_long_file.mp3", chunk_length_s=10, stride_length_s=(4, 2))
This technique is described in more details in this HuggingFace blog post.
Wav2Vec 2.0 XLS-R
The model used is based on Meta AI’s Wav2Vec 2.0, which uses self-supervision to learn the structure of speech from raw audio data. The method is explained in this blog post or in more detail in the paper “wav2vec 2.0: A Framework for Self-Supervised Learning of Speech Representations”.

To be precise, we are using this checkpoint which is the 300 million parameters version pretrained on 128 languages of the Wav2Vec2 XLS-R model, with audio sampled at 16kHz.
The method used for training is described in the paper “XLS-R: Self-supervised Cross-lingual Speech Representation Learning at Scale”
The Wav2Vec2 model, as described in the paper, is composed of
-
a “feature encoder” (represented on the image in blue, as ‘CNN’) which is a multi-layer convolutional network. There is only one such feature encoder, which performs a temporal convolution over the normalized raw waveform.
-
a “context network” (represented on the image in yellow as ‘Transformer’) which is a Transformer network.
The output of the feature encoder is fed into a convolutional layer, which acts as a relative positional embedding, and then into the context network.
To fine-tune this model on new supervised tasks, those latent representations can then be fed to randomly initialized layers that will be trained on the task we are interested in.
Adapting the model to the Speech Recognition task
As explained earlier, the base Wav2Vec2 model is made for self-supervised pre-training, so it will definitely not have the output format we want for a Speech Recognition task by default.
Speech Recognition
Speech recognition, also known as automatic speech recognition (ASR), computer speech recognition, or speech-to-text, is a capability which enables a program to process human speech into a written format.
The Wav2Vec2 model, as the name suggests, gets audio waveform as an input and outputs some vectors, or latent representations.
We will get from those latent representations to a text format via a “Language Model Head”, eg a classification head that, for every time-step of the audio processor outputs a probability of it being this or that letter.

We will need a “Vocabulary” that consists of all the characters that will be possible outputs.
The vocabulary that I used for the Romanian model is this one :
{"a": 1, "b": 2, "c": 3, "d": 4, "e": 5, "f": 6, "g": 7, "h": 8, "i": 9, "j": 10, "k": 11, "l": 12, "m": 13, "n": 14, "o": 15, "p": 16, "q": 17, "r": 18, "s": 19, "t": 20, "u": 21, "v": 22, "w": 23, "x": 24, "y": 25, "z": 26, "â": 27, "î": 28, "ă": 29, "ș": 30, "ț": 31, "|": 0, "[UNK]": 32, "[PAD]": 33}
It consists of the 31 letters of the Romanian alphabet, as well as some special tokens :
- ”|” (equivalent to the ϵ in the previous image) refers to the “void” token. It is also handy to make a distinction between the same letter that is stressed over multiple time-steps or two or more repetitions of the same letter.
- “[UNK]” is the token for unknown characters
- “[PAD]” is the token for padding (ie arbitrarly filling the space so every input is the same size)
So we will perform a classification between those 34 classes (31 letters + 3 tokens) for each time-step.
Obviously the speech recognition task is a little bit more complicated than that and will need a technique to handle the fact that the temporal mapping between the inputs and the outputs is inconsistent. One trick for this is called CTC, for Connectionist Temporal Classification.
Connectionist Temporal Classification (CTC)
Connectionist Temporal Classification, CTC for short, is a type of output for a model that allows to tackle sequence problems where the timing is variable.
For Speech to Text application such as Speech Recognition, the mapping of audio to text is not consistent and difficult to predict : some letters will be stressed for longer time than others. So a trick such as CTC that tackle this will be really helpful.


This problem can appear in various tasks, such as handwriting recognition, or what is our focus here, speech recognition.
CTC also refers to the associated loss function.
If you want to understand sequence modeling with CTC, make sur to check this article on Distill : “Sequence Modeling With CTC”.
Example with the transformers library
transformers is a python library that provides a really nice API to quickly download, use and fine-tune pretrained models for text, vision or audio.
Hopefully, the Wav2Vec2 model is implemented in the transformers library, and allows us to easily instantiate a connectionist temporal classification head and add it to our model, through the Wav2Vec2ForCTC class (or similarly with AutoModelForCTC).
from transformers import AutoModelForCTC, AutoConfig
model_path = "facebook/wav2vec2-xls-r-300m" #pretrained model path on the HuggingFace Model Hub
model = AutoModelForCTC.from_pretrained(model_path)
This warning should be prompted when instantiating the CTC version from the pretrained self-supervised checkpoint :
Some weights of Wav2Vec2ForCTC were not initialized from the model checkpoint at facebook/wav2vec2-xls-r-300m and are newly initialized:
['lm_head.bias', 'lm_head.weight']
And it is exactly what we want : to add a language model head (ie a text output) to the pretrained model.
The parameters of this head did not exist during the pre-training so they are initialized randomly and will need some fine-tuning.
To understand the whole pipeline to fine-tune a Wav2Vec2 acoustic model to a speech recognition task, you can refer to the Robust Speech Challenge guide on GitHub, the official training script for the event or the Hugging Face blog post.
Boosting the results with a Language Model
$n$-gram Language Model
A $n$-gram is a contiguous sequence of $n$ items of a sample.
In our case we will work with sequences of tokens from our alphabet (so the 31 Romanian letters + 3 special tokens). The language model that works with this data is called a character-level language model.
A $n$-gram model is a probabilistic model that predicts the next item only from the $n - 1$ previous items with a discrete-time Markov chain of order $(n - 1)$, ie it for a token $w_k$ in the position $k$,
\[{\rm I\!P}(w_k) = {\rm I\!P}(w_k\vert w_{k-n},...,w_{k-1})\]The probabilities can be estimated for a specific dataset by using the Kneser-Ney smoothing method for calculating probabilities of $n$-grams in a corpus.
Boosting the Speech Recognition Model results using a $n$-gram Language Model
The usual way to decode a CTC-trained network is through beam search decoding.
The beam search decoding, and how to add character-level language model, are explained in this article : Beam Search Decoding in CTC-trained Neural Networks
Check out this blog post from Patrick von Platen for a guide to use the kenlm and pyctcdecode libraries with HuggingFace’s transformers to boost the Wav2Vec2 CTC model results by adding a $n$-gram language model.
Boost the Speech Recognition Model results using a Transformer Language Model
It is possible to further improve the results of the model by using a transformer language model such as BERT, to boost the results of our Speech Recognition model.
You can refer to wav2vec 2.0: A Framework for Self-Supervised Learning of Speech Representations Table 9 Appendix C for comparing the results of decoding with a Transformer language model and a $4$-gram language model.
However, as I am writting this blog post, the pyctcdecode library does not yet implement Transformer language models.
And the Wav2Vec2ProcessorWithLM class from the transformers library only supports this library for CTC, LM-boosted output.
According to Patrick Von Platen in his article, a Transformer-language model gives better results than a $5$-gram language model but comes with a cost in computation that may not be worth-it for most use cases.
E.g., for the large Wav2Vec2 checkpoint that was fine-tuned on 10min only, an n-gram reduces the word error rate (WER) compared to no LM by ca. 80% while a Transformer-based LM only reduces the WER by another 23% compared to the n-gram. This relative WER reduction becomes less, the more data the acoustic model has been trained on. E.g., for the large checkpoint a Transformer-based LM reduces the WER by merely 8% compared to an n-gram LM whereas the n-gram still yields a 21% WER reduction compared to no language model.
The reason why an n-gram is preferred over a Transformer-based LM is that n-grams come at a significantly smaller computational cost. For an n-gram, retrieving the probability of a word given previous words is almost only as computationally expensive as querying a look-up table or tree-like data storage - i.e. it’s very fast compared to modern Transformer-based language models that would require a full forward pass to retrieve the next word probabilities.