On navigating with a faulty compass; Evaluating Language Models with Low-Quality References
Written on December 4th, 2024 by Théo Gigant
Illustration: And we continue fishing (Nicholas Roerich, 1922)
Evaluating Summarization Systems
State-of-the-art abstractive summarization systems are built on pretrained language models. These models are initially trained on a language modeling task and then fine-tuned for summarization tasks.
In order to assess the capability of a summarization system, it is essential to evaluate it on some benchmarks.
The standard pipeline involves a bunch of documents to summarize (preferably not seen during training) along with human-written reference summaries. The evaluation also includes a reference-based metric to compare the system-generated summaries against the reference summaries. One widely used metric is the ROUGE score, which computes the lexical overlap between the system-generated summary and the reference summary. The ROUGE score ranges from $0$ if no words are shared, to $1$ if both summaries use exactly the same words.
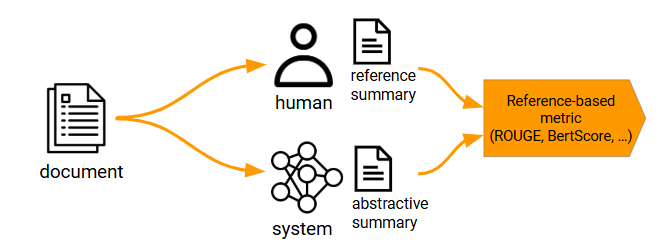
Reference-based evaluation pipeline
The method of evaluating summarization systems through reference-based metrics, such as ROUGE, relies on several assumptions that can be readily challenged:
- The reference summary for a given document is the optimal summary for that document. This is provably false for existing datasets, as illustrated by Maynez et al showing that 76.9% of the human-written reference summaries in the widely used XSum dataset contain hallucinated content. This highlights a significant flaw in the reliability of these reference summaries.
- The overall quality of a summary can be estimated by its distance to this reference summary. However Liu et al noted that human evaluation of system-generated summaries vary significantly depending on whether they have access to a reference summary. In both cases, the inter-annotator agreement is very low, suggesting that there is no clear consensus on what constitutes a high-quality summary.
- The set of documents used for evaluation is comprehensive enough to accurately compare different systems on the summarization task. Deutsch et al argue that the subsets used in meta-evaluation are often too narrow, leading to overlapping confidence intervals and unreliable system rankings. This indicates that the current evaluation datasets may not provide a robust basis for comparing summarization systems.
A more fine-grained evaluation pipeline can assess multiple qualities of summarization systems by evaluating them across several axes, such as:
- Relevance: The summary contains the main ideas from the source.
- Faithfulness / Factual Consistency: The facts are preserved between the source and the summary.
- Fluency: The linguistic quality of individual sentences.
- Coherence: The organization and structure of sentences.
Some metrics are designed to focus on one or more of these axes (eg ESTIME for faithfulness, GRUEN for fluency and coherence), while others compute the overall quality of the summaries (eg ROUGE, BertScore).
In our work “Mitigating the Impact of Reference Quality on Evaluation of Summarization Systems with Reference-Free Metrics”, we aimed to focus on the evaluation of relevance in summarization systems while assuming that the quality of the references is unknown.
Evaluating Summarization Systems with References of Unknown Quality
As we previously stated in Gigant et al, when working with web-scrapped datasets, the references usually come in different styles, lengths, contents and quality. This observation makes it tricky to work under the assumptions inherent to reference-based metrics. As a result, we are faced with the choice of either ditching the references and work with reference-free metrics, or ignoring the quality of the references and using reference-based metrics.
We chose to explore both directions, alongside a third hybrid option, and to try to quantify when each of these is the most relevant.
The reference-based metric we used is the ROUGE-1 score, for its simplicity and low cost. For the reference-free metric, we designed our own metric to avoid the higher cost of the LLM-as-a-judge method.
Designing a Reference-Free Metric for Relevance Evaluation
In order to design our metric, namely the Importance-based Relevance-Score, we focused on trying to find an easy and compute-cheap way to extract the main ideas from the source, by computing some meaningful overlaps between the document and the system-generated summary.
Meaningful Overlap vs Extractive Artifacts
In the neighbour field of Machine Translation, translationese refers to the non-idiomatic expressions and source language artifacts that appear in translated texts, whether produced by machines or humans. These elements often betray that the text was translated from another language. For example, translationese can manifest as the incorrect use of “false friends” (words that look similar in different languages but have different meanings) or literal translations of idioms. Such errors can reveal the translator’s native language and disrupt the natural flow of the text.
Freitag et al demonstrated that reference translations in machine translation datasets tend to exhibit such translationese language. They addressed this by creating new references through paraphrasing the existing ones. When tested, systems produces much lower lexical overlap with the paraphrased references compared to the translationese ones, but the correlation with human judgement was higher.
They observed that the lexical overlaps with the paraphrased references were less numerous but more meaningful than with the translationese ones, as they were more related to the semantic meaning of the sentence rather than the structure of the sentence.
Inspired by these, we proposed a translationese-extractiveness analogy to extrapolate these findings to the domain of summarization by observing that extractive fragments in summaries (ie fragments of the summaries that are directly extracted from the source) share similarities with translationese. Both are artifacts of the source and can be mitigated by paraphrasing in order to keep the semantic similarity while reducing the sentence structure similarity.
To translate the findings of Freitag et al to our own case, we would need to rephrase every reference summary to erase the “extractive artifacts” and provide more meaningful overlaps with reference-based metrics. Or we could go another way and find a way to filter out the overlaps related to the sentence structure, and keep only the meaningful overlaps.
An easy and compute-cheap method to estimate the meaningful words in a document is inspired by the information retrieval domain: the TF-IDF (Term Frequency - Inverse Document Frequency) method introduced by Karen Spärk Jones in 1972 is a very strong baseline for information retrieval in textual documents, and it uses word statistics to estimate the importance of a word to a document in a corpus.
We use this method to derive an importance score for every word in the document before performing an importance-weighted lexical overlap between the system-generated summary and the document.
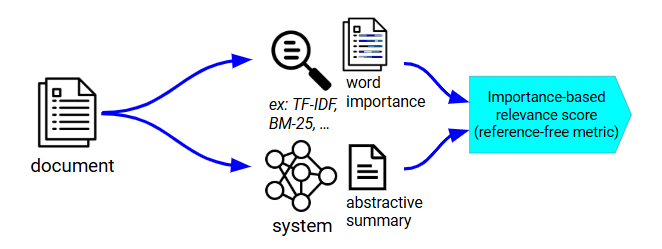
Our reference-free evaluation pipeline
Our paper provides a detailed description of the construction of this metric, and shows that it performs on-par with other reference-free metrics such as LLM-as-a-judge for relevance evaluation, for a significantly lower computational cost.
Assessing the Impact of Reference Quality on Evaluation
The usefulness of an evaluation metric is assessed through a meta-evaluation on various benchmarks. These meta-evaluations consist of documents, human-written reference summaries, and system-generated summaries from a variety of systems. Each system-generated summaries are then graded by human evaluators.
A good metric should correlate closely with human ratings of the system-generated summaries. This behavior is quantified by the system-level correlations between the metric and the human evaluations, indicating how well the metric aligns with human judgment.
To assess how the reference quality impacts the system-level correlation with human evaluation, we need to define a method to artifically decrease the reference quality. We chose to gradually replace random references with low quality ones, using three random sentences from the document.
By design, a reference-free metric is not impacted by the reference quality, thus it will appear as a horizontal line.
However a reference-based metric, such as ROUGE-1, will show correlation with human evaluation decreasing with lower reference quality, as we could have suspected.
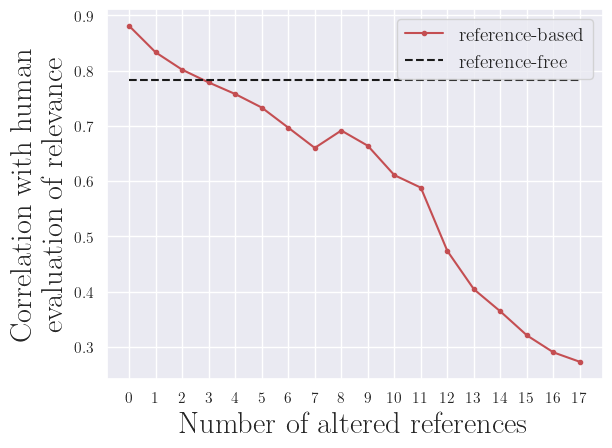
a) arXiv dataset
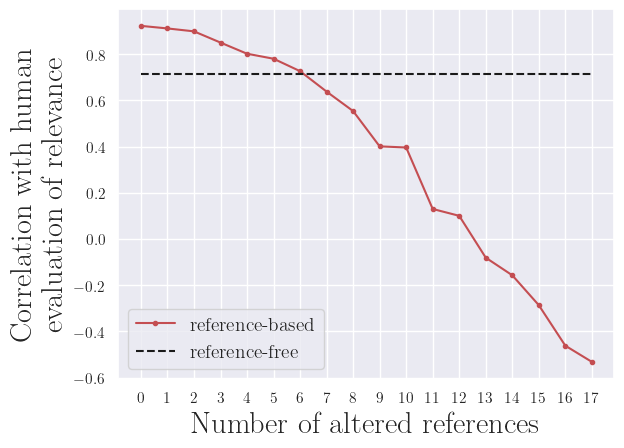
b) GovReport dataset
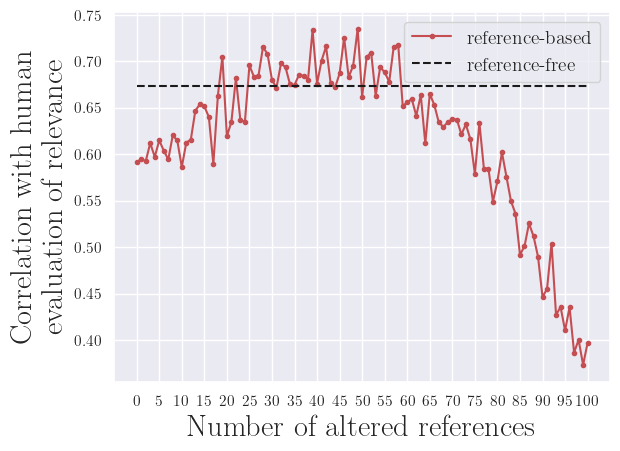
c) SummEval dataset
The main finding in our work is that a simple combination of reference-based and reference-free metrics results in a new metric that maintains high correlations with human evaluation, similar to a reference-based metric, while also demonstrating greater robustness to lower reference quality. We combined the scores of a reference-based metric (ROUGE-1) and a reference-free metric (our Importance-based Relevance-Score) by averaging them. This combined metric not only aligns well with human judgments but also remains effective even when the reference quality is low, making it a more reliable tool for evaluating system performance.
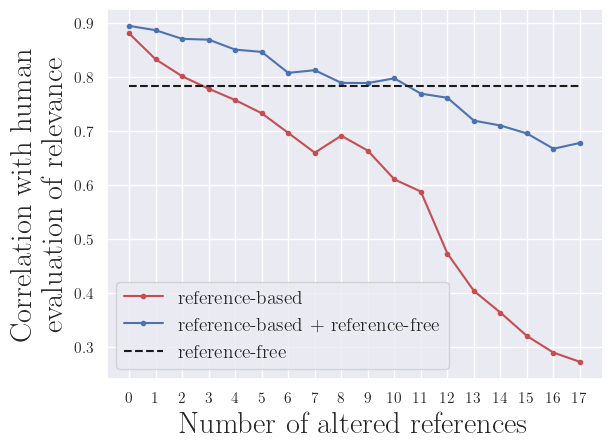
a) arXiv dataset
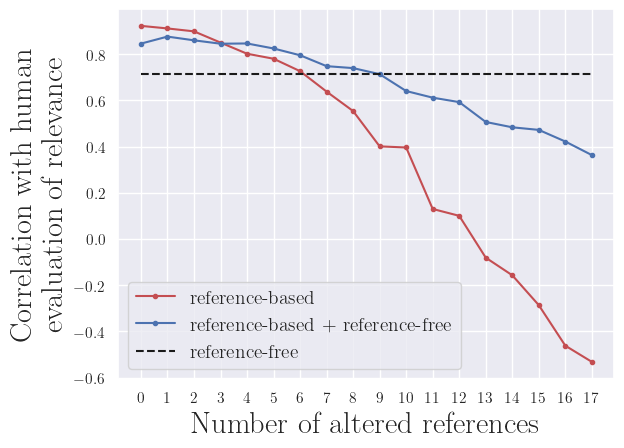
b) GovReport dataset
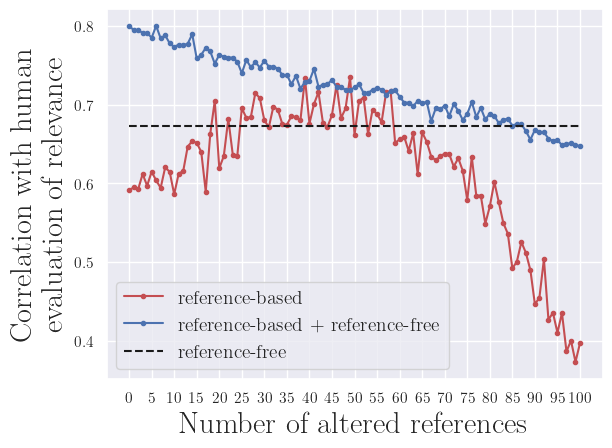
c) SummEval dataset
Conclusion
Based on our preliminary findings, we recommend the use of combined reference-free and reference-based metrics to enhance robustness in scenarios with low-quality references. This approach not only maintains high correlation with human evaluation but also improves reliability in settings where the reference-quality is unknown, eg working with web-scraped datasets.
We believe that this work highlights the need for further research on this phenomenon, particularly in different tasks and with various metrics. Future studies could explore more sophisticated combination methods, such as estimating reference quality to dynamically weight the contributions of reference-based and reference-free metrics.
“Mitigating the Impact of Reference Quality on Evaluation of Summarization Systems with Reference-Free Metrics”, was published as a short conference paper at EMNLP 2024.